GRADE 實證教學!評估「證據品質」和「建議強度」的系統化做法

GRADE 是什麼?
GRADE 是一套評估(1)證據品質和(2)建議強度的方法。
由方法學家、指引制定者、臨床醫師、研究員、經濟學家、公衛學者…等多領域專家於 2000 年所建立。
誰有在使用 GRADE?
國內外的許多指引都陸續開始使用 GRADE 作為評等標準。
除此之外 GRADE 也時常被用來撰寫「系統性回顧」和「統合分析」。其中「系統性回顧」的權威單位「考科藍」在較新的研究中,幾乎都會使用到 GRADE。
如果你是參加實證醫學競賽的人,應該也會發現越來越多得獎團隊會在簡報中加入 GRADE。由此可知,GRADE 在國內外的不同應用上都有越來越普遍的趨勢。
- 國內指引
- 考科藍系統性回顧
- 外國指引
GRADE 有哪些特色?
- 用統一的標準評讀「證據品質」和「建議強度」
- 降級和升級的規則明確
- 讓證據到建議的過程公開透明
GRADE 分為哪些等級?
證據品質
| 證據品質等級 | 描述 |
|---|---|
| 高 (High) | 作者對真實效果與估計效果相似有「很高的信心」 |
| 中等 (Moderate) | 作者認為真實效果可能接近估計效果 |
| 低 (Low) | 真實效果「可能」(might)與估計效果有顯著差異 |
| 非常低 (Very low) | 真實效果「較可能」(probably)與估計效果有顯著差異 |
建議強度
- 強烈建議(Strong, Favor)
- 薄弱建議(Weak, Favor)
- 薄弱反對(Weak, Against)
- 強烈反對(Strong, Against)
證據品質與建議強度並不是完全獨立,通常較弱的證據品質,也會得出較弱的建議強度。
證據品質怎麼評分?
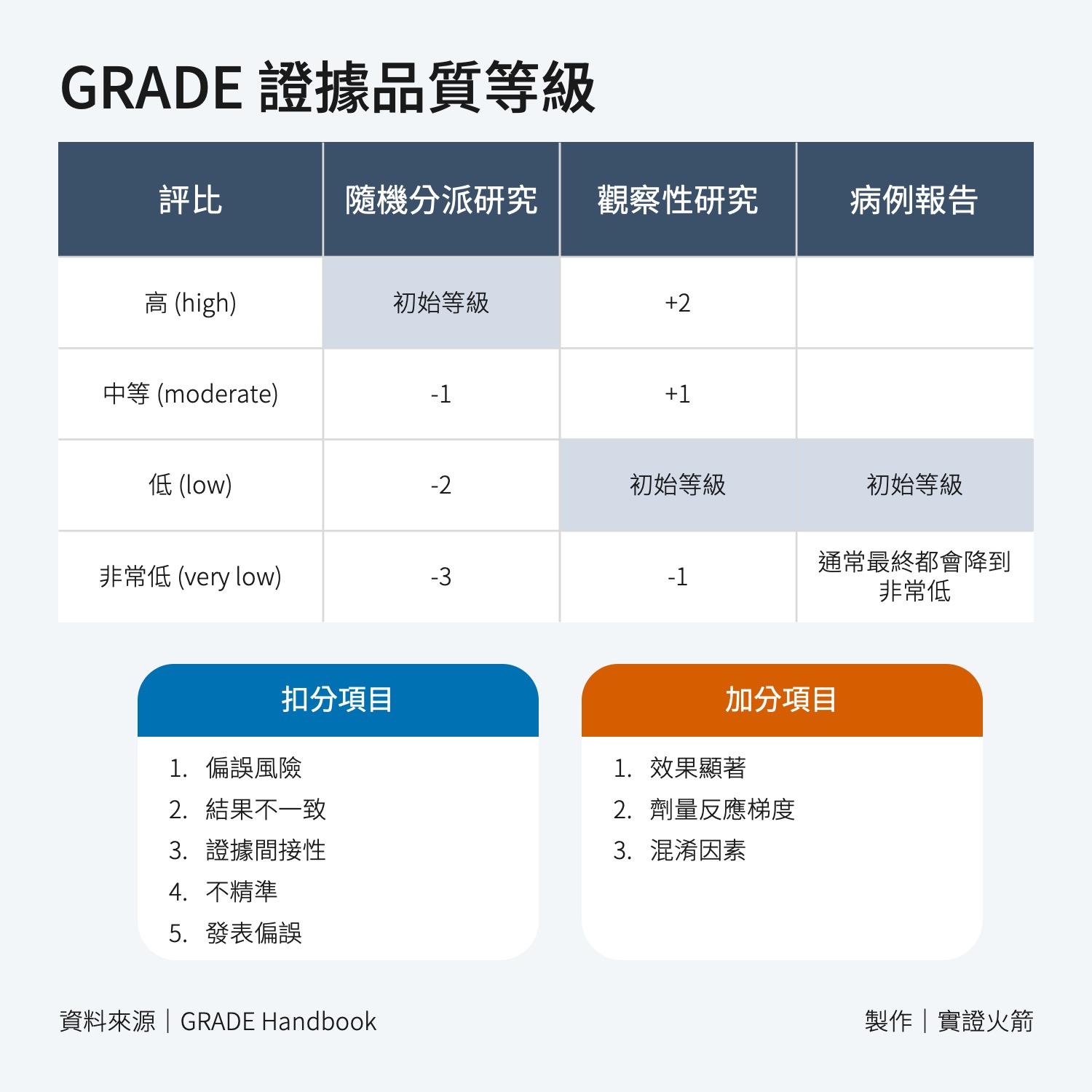
每一個項目可以扣的分數不同,請參考下表:
舉例
- 某篇 RCT 扣兩分,就會得出低 (Low) 的證據品質
- 某篇觀察性研究扣一分,就會得出非常低 (Very low) 的證據品質
其他研究類型
- 準隨機對照試驗(Quasi-RCT):雖然初始評分跟 RCT 一樣為高 (High),但他一定會因為研究設計被在「偏誤風險」項目被扣分。
- 病例報告(Case Report):屬於一種「觀察性研究」,所以初始分數為低 (Low),但會因為「對照組」不明確,通常都會被降到非常低 (Very Low)
- 專家意見(Expert Opinion):在 GRADE 當中不納入證據品質。
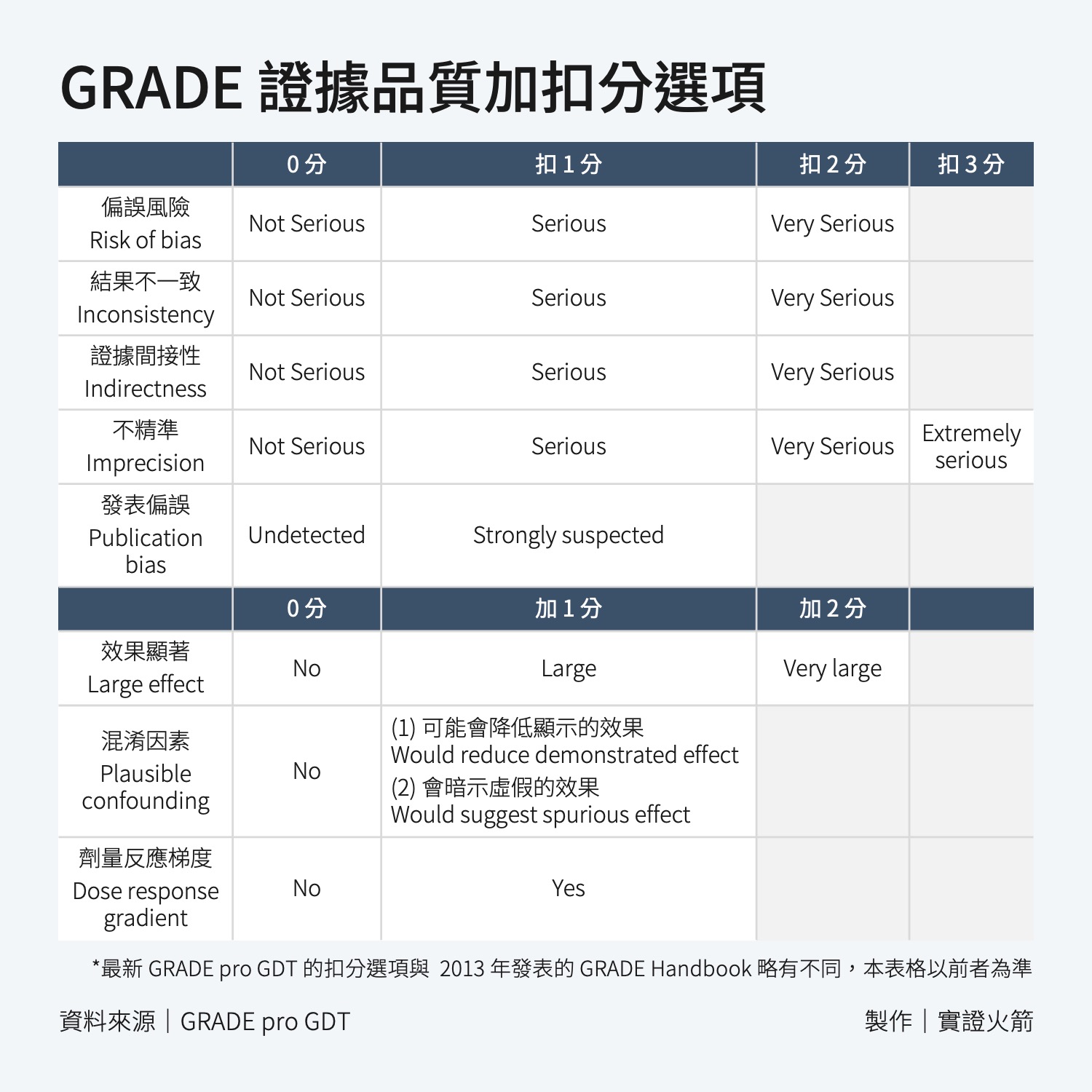
加分與扣分項目教學
扣分項目 1:偏誤風險 (Risk of Bias)
你可以使用考科藍提出的 Risk of Bias 2.0 來評讀,也可以參考 GRADE 的官方手冊。
GRADE 官方手冊中提到,RCT 常見的 Bias 包括:
- 缺乏分派隱匿
- 登記病人的人知道下一個登記的病人將被分配到哪一組
- 準隨機試驗(Quasi-RCT):按星期幾、出生日期、病歷號碼等分配
- 缺乏盲性
- 病人、照護者、記錄結果的人、裁定結果的人或數據分析師知道病人被分配到哪一組
- 病人和結果事件的不完整記錄
- 在優越性試驗中,未按意向分析(Intention-to-treat)可能會造成偏誤。
- 在非劣性試驗中,應該比較「依計畫書治療的患者」(Per-Protocol) 與「所有有結果數據的患者」的差異。
- 失聯患者的比例對研究結果影響很大。如果失聯比例高,尤其是介入組和對照組的事件率差異較大時,偏誤風險就更高。
- 選擇性結果
- 這是指研究人員根據結果的好壞,只報告部分結果,而不報告其他結果。
- 其他限制
- 為了影響結果提早停止試驗
- 使用未經驗證的結果測量方法
- 交叉試驗中延續的治療效果
- 群組隨機試驗中的招募偏誤:比如用兩校的學生當成 A、B 組。一組來自城市,一組來自鄉下,就會有招募偏誤。
如果使用的是 RoB 2.0,可以對照下圖來轉換成 GRADE 的標準。

扣分項目 2:結果不一致
評估的標準有三個:
- 各研究中的點估計值差異很大:這通常指的是不同研究報告的效果大小(例如治療效果、風險比、平均差等)存在顯著的變異。
- 信賴區間(CI)只有很小部分重疊或完全沒有重疊。
- 客觀的「異質性數據」(P 值或 I2 值)達到顯著水準。
GRADE 提供的 I2 評斷標準:
- < 40%:可能是「偏低」
- 30-60%:可能是「中等」
- 50-90%:可能是「大」
- 75-100%:可能是「相當大」
之所以會有重疊,是因為 I2 會受樣本數影響,所以有不確定性。另外也可以參考不依賴樣本量的 τ2(tau square)。
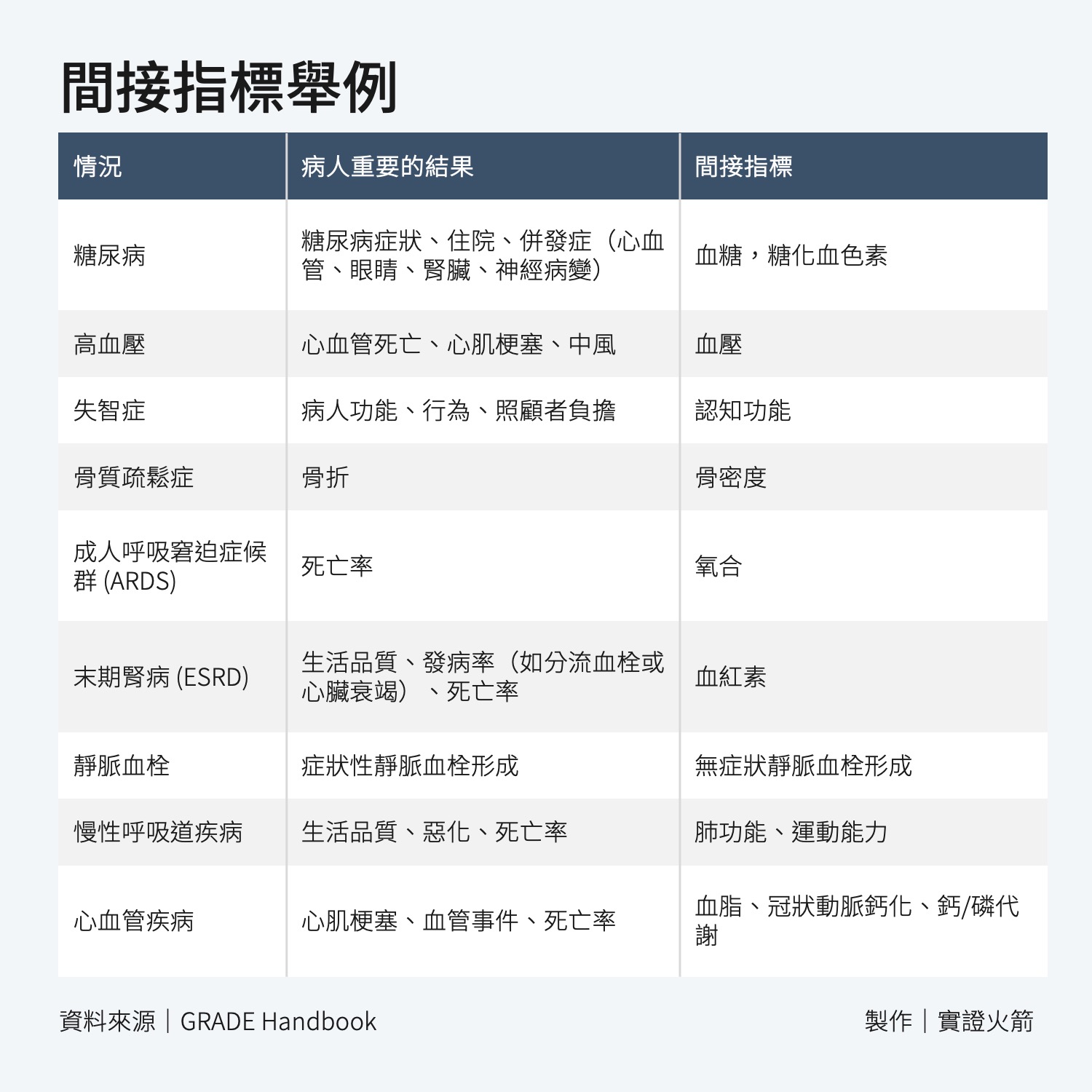
扣分項目 3:證據間接性
簡單來說就是比較你感興趣的 PICO 跟研究是否相符。
常見的間接性來源有四種:
- P 人口差異
- I 介入措施的差異
- O 結果測量的差異(如:結果評估的時間長度不理想、間接指標)
- 間接比較
間接指標是什麼?
一般來說,使用間接指標需要將證據質量降低一個或甚至兩個等級。
間接比較是什麼?
當無法直接比較介入措施 A 和 B 的效果時,如果已有研究分別比較了 A 與 C 以及 B 與 C,我們可以通過這些研究間接推斷 A 與 B 的效果差異。然而,由於這是間接比較,這種證據的可信度通常低於直接比較 A 與 B 的證據。
網狀統合分析 (Network Meta-analysis) 也屬於一種間接比較,通常需要降級。
間接比較舉例:當無法直接比較低劑量和中劑量阿司匹林的效果時,研究者們通過比較兩者與安慰劑的效果,間接推斷了它們之間的差異。結果顯示中劑量可能比低劑量更有效,但這種間接比較的證據不如直接比較可靠。
扣分項目 4:不精確
評估不精確的標準有兩個:
- 信賴區間是否跨過了「閾值」?
- 是否達到最佳資訊量 (optimal information size; OIS)
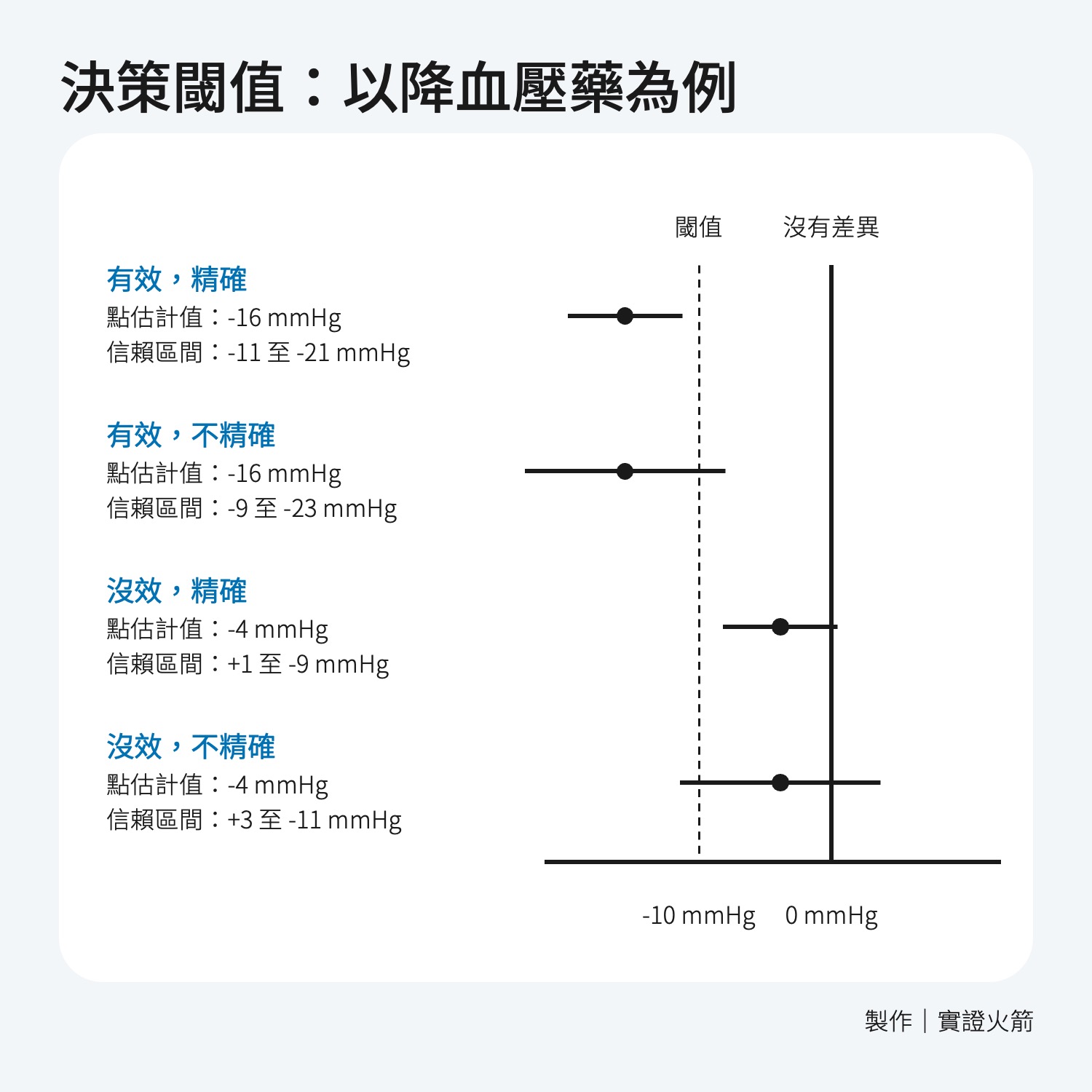
什麼是閾值?
這個臨界值通常基於臨床經驗、患者的情況、治療的風險和收益等多種因素來設定。例如,如果某個治療的效果(如降低血壓)達到了這個臨界值,那麼醫生就會決定採取這個治療;反之,如果效果沒有達到這個臨界值,則可能不會採取這個治療措施。
閾值舉例:
假設有一個臨床試驗在評估一種新藥對降低血壓的效果。臨床決策閾值可能是「降低收縮壓至少10 mmHg」。
如果試驗結果顯示新藥能降低收縮壓至少 10 mmHg,醫生可能會使用該新藥;如果效果低於10 mmHg,醫生可能不會使用該新藥。
什麼是 OIS (Optimal Information Size)?
OIS(最佳資訊量)是指「為了得到可靠結果」所需的最小樣本量,可以使用計算程式幫忙計算,以下為輸入的案例。
- 我們是要計算達到「特定檢定力」需要的樣本數,所以勾選「Calculate Sample Size」
- p1: 服用 A 藥者,中風的比例為 5%,所以輸入 0.05
- p2: 服用安慰劑者,中風的比例為 3.5%,所以輸入 0.035
- 由於我想知道 A 藥會「增加」或「減少」中風的風險,所以選擇「2 Sided Test」
- α (Alpha):預設為 0.05,代表我們願意接受 5% 的概率,實際上沒有差異時,結果卻顯示有顯著差異的機率。
- Power:預設為 0.8,代表如果 A 藥真的有效,我們有 80% 的概率能檢測到這樣的結果。
- 備註:Alpha 是用來表示 Type 1 error,代表「其實 A 藥沒效,但研究結果讓你以為有效」Power 是用來表示 Type 2 error,代表「A 藥其實有效,但研究結果讓你以為沒效」。
將以上的數據輸入到網頁裡,就能得到各組需要「2838」人,也就是總共要收 5676 位受試者。

扣分項目 5:發表偏誤
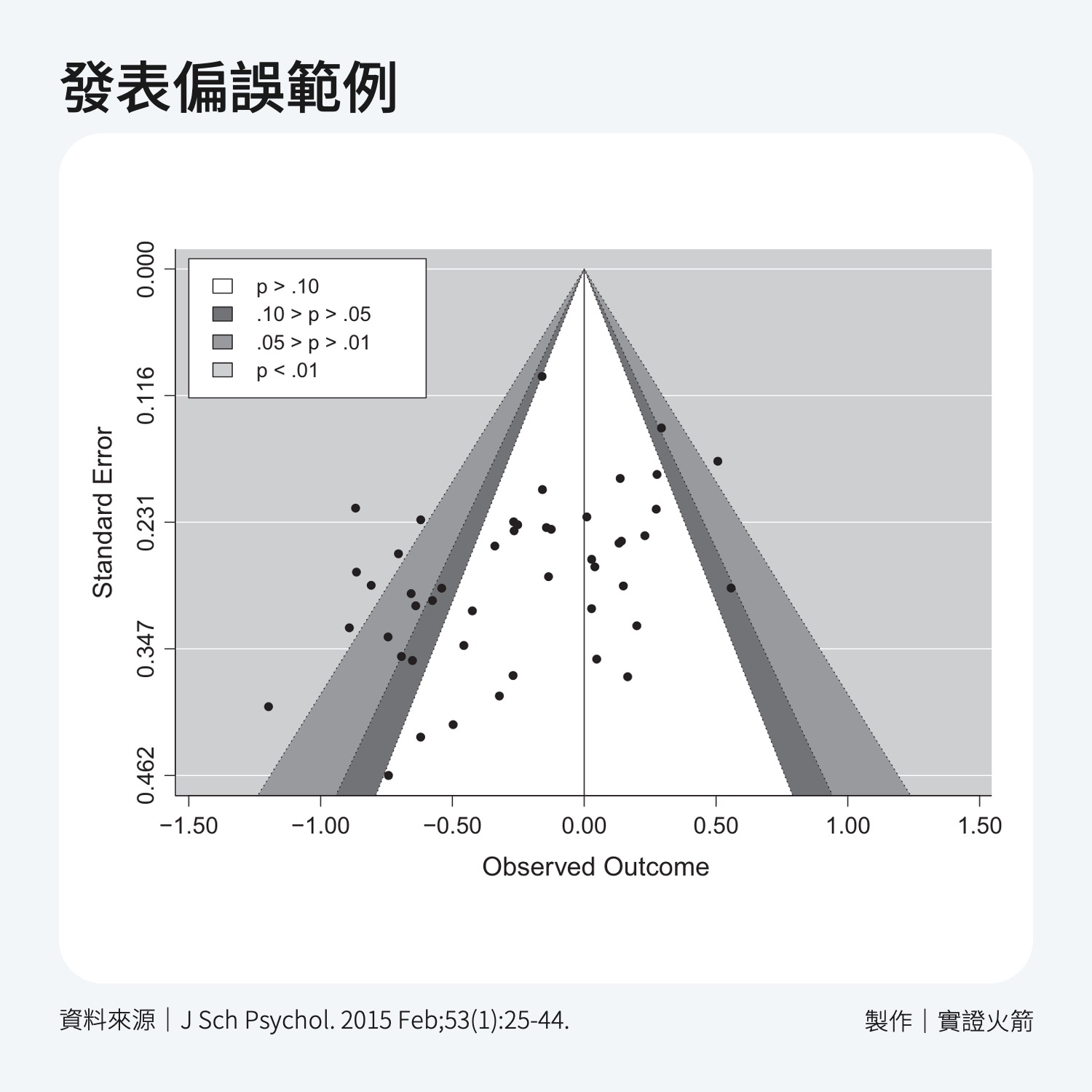
根據過去的經驗,得出「有顯著差異」的研究比沒有顯著差異的研究更容易被刊登,這會造成統合分析時的偏誤,我們稱之為「發表偏誤」。
研究中通常會用「漏斗圖」來展示發表偏誤,圖片的越上面代表「越精確」的研究,通常是「樣本數」較大的研究。
圖片的橫軸則代表研究結果,若是以剛剛降血壓藥的研究為例,右邊就會代表「血壓上升」,左邊就會代表「血壓下降」。
如果漏斗圖不對稱,通常代表有較嚴重的「發表偏誤」,就像下面這張圖右下角缺了很多研究。
加分項目說明
- 加分並不常見
- 加分在要扣分之後進行:
這點很好理解,如果在扣分時發現研究有很多不嚴謹的地方,即使得出「效果顯著」,你大概也不會覺得這個結果可信吧?所以在這種情況,就不會加到分。 - 加分項目主要用於「觀察性研究」:
雖然 RCT 「理論上」也能加分,但 GRADE 官方手冊表示這種情況非常少見。
加分項目 1:效果顯著
通常用於「沒有」被扣到任何一分的「觀察性研究」。
| 效果大小 | 定義 | 證據品質等級 |
|---|---|---|
| 大 Large | 相對風險 RR >2 or <0.5 | 最多增加 1 級 |
| 非常大 Very Large | 相對風險 RR >5 or <0.2 | 最多增加 2 級 |
除了相對風險 (RR) 以外,還有其他造成效果顯著的可能
- 效果快速
- 效果在不同受試者族群中一致
- 先前疾病發展趨勢被逆轉
- 舉例:原本慢性腎病的病程會隨著時間推移惡化,如果有一款新藥在觀察性研究中有足夠證據可以明顯逆轉這個趨勢,可以考慮在 GRADE 中加分。
- 間接證據支持效果的巨大程度
加分案例
一項系統性回顧觀察性研究發現,嬰兒採取(趴著)比仰臥(躺著)睡姿的猝死症(SIDS)發生機率高出4.1倍(95% CI: 3.1, 5.5)
此外,自1980年代開始的「仰睡」運動在多個國家使 SIDS 的發生率相對下降了50-70%。

加分項目 2:劑量反應梯度
劑量梯度是指劑量增加時效果也增加,這能增強我們對觀察結果的信心,因為他支持因果關係的存在。
抗生素「給藥速度」與「敗血症和低血壓患者」的死亡率呈劑量反應梯度,每延遲一小時給藥,死亡率顯著增加。這種劑量反應關係增強了我們對死亡率影響的信心,從而提升證據質量。
加分項目 3:混淆因素
這個名詞非常的不白話,但並沒有想像中的難懂。混淆因素可能會低估或高估介入的效果。
低估的案例
一項研究調查了 COVID-19 疫苗接種對感染率的影響。觀察性研究顯示,接種疫苗的人感染風險較低(相對風險為 0.50)。但研究沒有考慮到,接種疫苗的人可能原本就是高風險人群(如經常出國或醫護人員),他們更頻繁地暴露於病毒,因此疫苗的實際效果可能被低估了。
在 GRADE pro 網站中,低估的案例要選擇「would reduce demonstrated effect」選項。
高估的案例
假設我們進行了一項觀察性研究,調查 A 疫苗與自閉症的關聯。結果顯示,接種與未接種 A 疫苗的兒童之間,自閉症發病率無顯著差異。
在這項研究中,可能存在一些混雜因素,如:
- 家長因為看到媒體報導而過度報告自閉症的症狀
- 醫生在知道兒童接種 A 疫苗後更去注意自閉症的症狀
這些因素都可能「增加」A 疫苗與自閉症之間的觀察關聯。然而,即便在可能高估 A 疫苗與自閉症的關聯下,還是沒有統計上的顯著差異。這會讓我們更偏向相信 A 疫苗與自閉症無關。
這種會讓 A 疫苗與自閉症的關聯被高估的現象稱為「Spurious effect (虛假效果)」。所以在 GRADE 網站中,要選擇「would suggest spurious effect」選項
建議強度教學
GRADE 系統中決定建議強度的主要因素有以下四個:
要素一:好處與壞處
- 估計效果:透過上述研究評讀,你預期的好處與壞處有多大?
- 結果的重要性:並不是所有研究結果對病人都是等同重要的。
要素二:價值與偏好
- 資源充足的情況下,應該要「實際詢問」到患者本人,或能夠代表他們的人。
- 資源不足的情況下,可以透過現有文獻來推測患者的價值與偏好。
要素三:證據品質
- 通常「強烈建議」至少要來自於中等(Moderate)或高(High)的證據品質。
以下狀況可能在證據品質低的情況下,給出強烈的建議強度:

總結筆記
如果要像「指引制定者」一樣嚴謹的評讀 GRADE,所需要的知識還有很多很多。
但相信透過上面的步驟,即使是初學者,也能對 GRADE 有基本的認識,並且做出一份「有價值」的 GRADE 表格。
參考資料
Schünemann H, Brożek J, Guyatt G, Oxman A, eds. Handbook for grading the quality of evidence and the strength of recommendations using the GRADE approach. Updated October 2013.
劉人瑋. GRADE證據等級與建議強度評比系統簡介. 簡報於: 萬芳醫院; 2014年10月4日; 台北, 台灣. 新光吳火獅紀念醫院.
吳易澄. [實證]GRADE workshop 心得筆記. https://wycswimming.blogspot.com/2018/07/GRADE.html. 發表於2018年7月. 閱讀於2024年7月13日.
Siemieniuk R, Guyatt G. What is GRADE? BMJ Best Practice. https://bestpractice.bmj.com/info/us/toolkit/learn-ebm/what-is-grade/. Accessed July 13, 2024.